Nim 实战

|
这个指南原来是为 Nim 实战写的. 由于书的篇幅限制,最终没有出现在书中。《Nim实战》的编写风格与本指南类似,请查看它以了解有关 Nim 编程语言的多信息。 |
|
Tip
|
折扣
使用折扣码 fccpicheta 可享受《Nim in Action》的37%折扣。
|
|
|
这个指南原来是为 Nim 实战写的. 由于书的篇幅限制,最终没有出现在书中。《Nim实战》的编写风格与本指南类似,请查看它以了解有关 Nim 编程语言的多信息。 |
|
Tip
|
折扣
使用折扣码 fccpicheta 可享受《Nim in Action》的37%折扣。
|
本指南将介绍一些实用工具,用于文档、分析和调试Nim代码。内容包括:
Nim 的注释文档中使用的 reStructuredText 语言
Nim 程序性能和内存使用分析器
一起使用 Nim 和 GDB/LLDB
准备好 Nim 编译器,并按照本指南中的使用。
代码文档很重要。它解释了有关软件的具体细节,这些细节在查看库的 API 甚至软件的源代码时并非显而易见。
有许多方法可以写代码文档。你可能知道,像许多编程语言一样,Nim支持注释。源代码的注释,是使源码更易于理解的一种方式。
在Nim中,单行注释由字符 # 分隔。
多行注释可以用 #[ 和 ]# 。
Listing 1.1 给出两种注释的例子。
var x = 5 # 把 5 赋值给 x.
#[多行-
的 (1)
注释]#这种语法仍然相对较新,因此大多数语法高亮显示者都不知道它。
Nim还支持一种特殊类型的注释,称为文档注释。
这种类型的注释由 Nim 的文档生成器处理。使用两个 ## 字符开头的的注释就是文档注释。
## 这是模块``test``的 *文档注释* 。<list_1_2,清单1.2>> 显示了一个非常简单的文档注释。
Nim 编译器包含一个为给模块生成文档的命令。将 <list_1_2,清单1.2>> 中的代码保存为文件 test.nim ,然后执行 nim doc test.nim 。在 test.nim 文件旁边应该生成一个 test.html 文件。在您喜爱的浏览器中打开它,查看生成的HTML。您应该会看到类似于 [fig_1_1,图1.1] 中截图的内容。
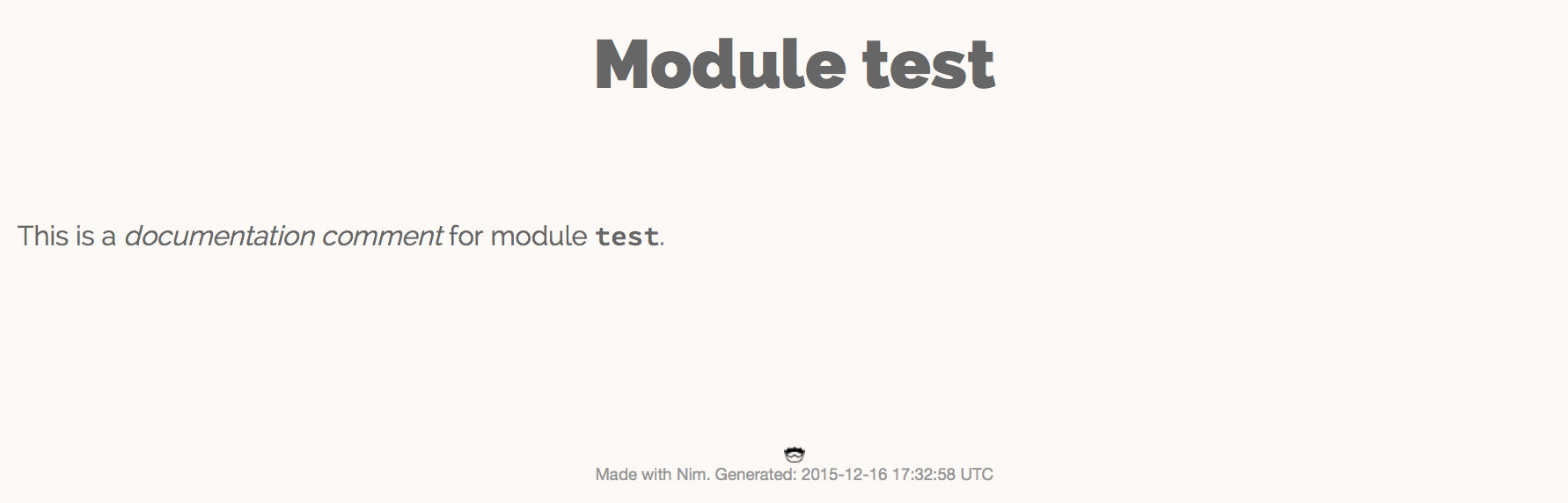
test.nim 模块的 HTML 文档请注意屏幕截图中不同的文本格式。文本 “文档注释” 为斜体,因为它在文档注释中被星号( * )包围。“测试”由两个反引号包围,这使得字体具有单间距,在显示变量名之类的标识符时非常有用。
这些特殊分隔符是文档生成器支持的 reStructuredText 标记语言的一部分。
文档生成器读取您在命令行上指定的文件,查找所有文档注释,然后遍历其中的每个注释。
每个文档注释都使用 reStructuredText 解析器进行解析。然后,文档生成器基于其解析的 reStructuredText 标记生成HTML。
表格 1.1 显示了 reStructuredText 标记语言的一些示例语法。
| 语法 | 结果 | 用法 |
|---|---|---|
|
italics |
强调单个词 |
|
bold |
黑体重点强调 |
|
|
名称标识符: 变量, 过程, 等. |
|
链接到其他Web页面 |
|
|
|
"=" 后可以是任何标点符号,标题的级别由连续的标题决定。 |
echo("Hello World")
|
|
代码例子。可以给代码添加语法高亮显示。 |
有关更全面的参考信息,请查看链接: http://sphinx-doc.org/rest.html
看看其他的例子。
## 这是世界上最好的模块
## 我们有很多文档
##
##
## 例子
## ======
##
## 下面显示些例子:
##
##
## 将两个数字相加
## ---------------------------
##
## .. code-block:: nim
##
## doAssert add(5, 5) == 10
##
proc add*(a, b: int): int =
## 将整数 ``a`` 和整数 ``b`` 相加后返回结果。
return a + b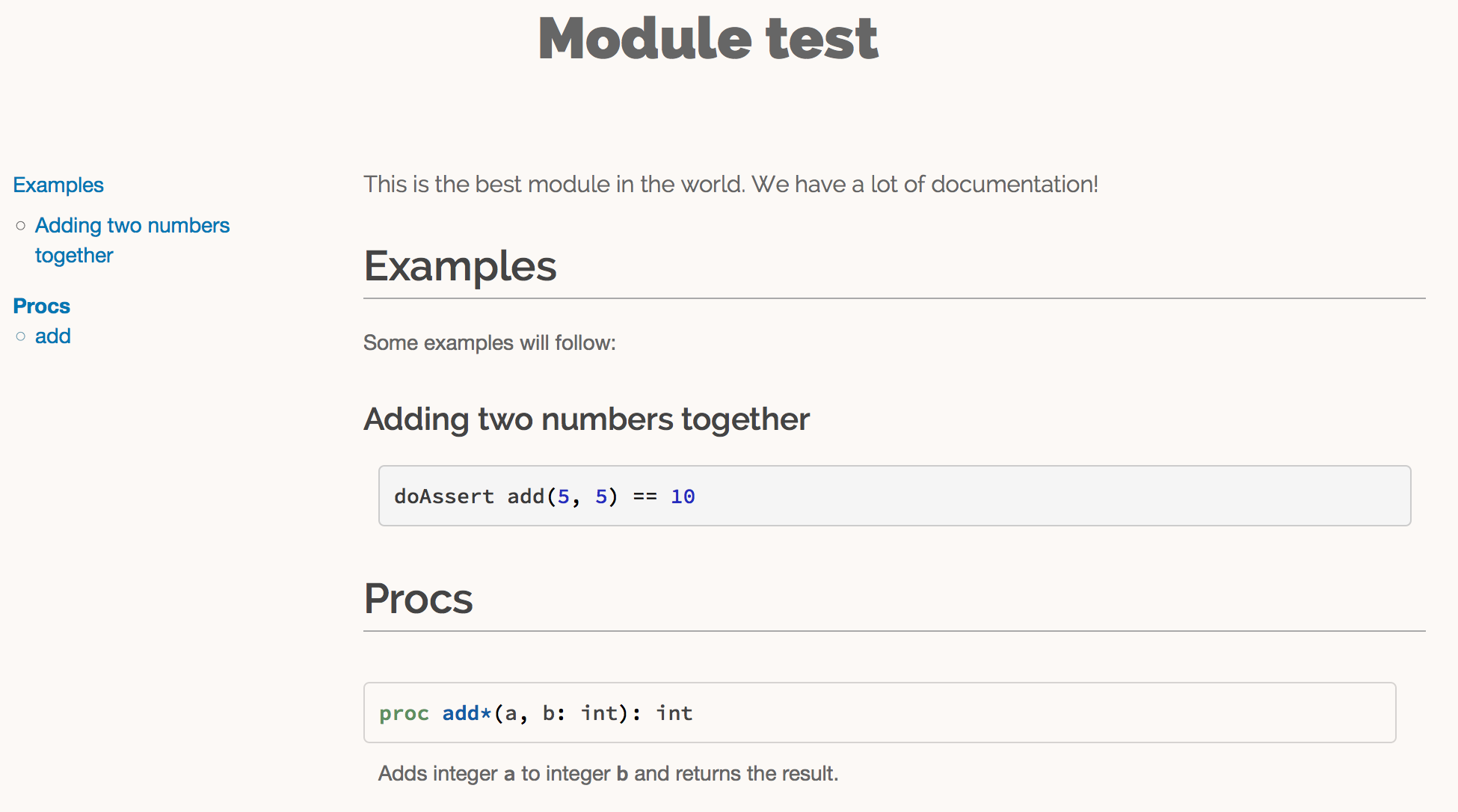
从 [list_1_3,清单1.3] 中的示例中可以看到,文档注释可以放在许多地方。它们可以是全局范围内的,也可以是程序下的局部范围内的。程序文档下的文档注释与该程序的作用范围相同,Nim文档生成器生成模块中导出的所有程序的列表,具有文档注释的程序将显示在下面,如 [fig_1_2,图1.2] 所示。
这就是 Nim 标准库生成文档的方式。有关如何编写文档的更多示例, 可以看看https://github.com/nim-lang/Nim/tree/devel/lib/pure[其源代码]。
分析应用程序,就是在运行时分析应用程序,确定其花费时间做什么的行为。例如,它大部分时间用在哪些过程,或者每个过程被调用了多少次。
这些分析可以帮助查找需要优化的代码。有时,也可以帮助查找应用程序中的错误。
Nim 编程语言有大量的分析器可用。
这可能会令人惊讶,因为 Nim 是一个相对较新的语言。事实上,这些分析器中的大多数都不是专门为 Nim 创建的,而是为 C 创建的。C 分析器支持 Nim 应用程序,因为 Nim 编译为 C 。要利用这些分析器,您只需要知道一些事情。
Nim 编译器中实际上包含了一个分析器,它是迄今为止唯一一个为分析 Nim 应用程序而设计的分析器。在转到 C 分析器之前,让我们先看看它。
嵌入式堆栈跟踪分析器(ESTP) ,被称为 NimProf ,是标准 Nim 发行版中包含的Nim 分析器。要激活此分析器,只需执行以下步骤:
将 nimprof 模块导入程序的主 Nim 模块(您将要编译的模块),
使用 --profiler:on 和 stacktrace:on 标志编译程序。
和平常一样运行程序。
|
Note
|
应用程序速度
由于加入了分析的原因,应用程序将运行的更慢,这是因为分析器需要在运行时分析应用程序的执行,这会产生明显的开销。
|
看看以下代码列表。
import nimprof (1)
import strutils (2)
proc ab() =
echo("Found letter")
proc num() =
echo("Found number")
proc diff() =
echo("Found something else")
proc analyse(x: string) =
var i = 0
while i < x.len:
case x[i] (3)
of Letters: ab()
of {'0' .. '9'}: num()
else: diff()
i.inc
for i in 0 .. 10000: (4)
analyse("uyguhijkmnbdv44354gasuygiuiolknchyqudsayd12635uha")首先导入 nimprof 模块,才能使用分析器。
Letters 集合在 strutils 中定义。
迭代字符串 x 中的每个字符,如果是字母调用 ab ;如果是数字则调用 num ;如果是其他字符,则调用 diff 。
我们执行了 10000 次函数,以便让分析器可靠测量。
将其保存为 main.nim ,然后通过执行 nim c --profiler:on --stacktrace:on main.nim 来编译它。编译成功后您可以运行它。程序执行完毕后,您应该会在终端窗口中看到类似于 "writing profile_results.txt…" 的消息。
main 程序会在当前工作目录中创建一个 profile_results.txt 文件,内容应与 [listing_1_5,清单1.5] 相似。
total executions of each stack trace:
Entry: 1/4 Calls: 89/195 = 45.64% [sum: 89; 89/195 = 45.64%]
analyse 192/195 = 98.46%
main 195/195 = 100.00%
Entry: 2/4 Calls: 83/195 = 42.56% [sum: 172; 172/195 = 88.21%]
ab 83/195 = 42.56%
analyse 192/195 = 98.46%
main 195/195 = 100.00%
Entry: 3/4 Calls: 20/195 = 10.26% [sum: 192; 192/195 = 98.46%]
num 20/195 = 10.26%
analyse 192/195 = 98.46%
main 195/195 = 100.00%
Entry: 4/4 Calls: 3/195 = 1.54% [sum: 195; 195/195 = 100.00%]
main 195/195 = 100.00%当应用程序运行时,分析器会对当前正在执行的每行代码进行多个快照。它会记录堆栈跟踪,说明应用程序是如何执行这段代码的。然后在 profile_results.txt 中报告最常见的代码路径。
在 [listing_1_5,清单1.5] 中所示的报告中,分析器创建了195个快照。
它发现,在 45.64% 的快照中,正在执行的代码行在 analyze 过程中。在 42.56% 的快照中,它处于 ab 过程,这是有意义的,因为传递给 analyze 的字符串主要由字母组成。数字不太多,因此 num 过程的执行仅占这些快照的10.26%。
分析器未发现 diff 过程的任何调用,因为 x 字符串中没有其他字符。尝试在传递给 analyze 过程的字符串中添加一些标点符号,您会发现探查器结果会显示 diff 过程。
在不使用分析器的情况下,很容易确定 [listing_1_4,清单1.4] 中的大部分处理发生在哪里。
但对于更复杂的模块和程序, Nim 分析器对于分析最常用的函数非常有用。
|
Tip
|
内存使用情况
Nim分析器还可以分析内存使用情况,使用 --profiler:off --stackTrace:on ,和 -d:memProfiler 标志编译程序。
|
Valgrind 分析不好的是,Valgrind 分析器不是跨平台的。如果你是Windows用户,恐怕你将无法使用它。
Valgrind 不仅仅是一个分析器,它主要是一个用于内存调试和内存泄漏检测的工具。分析器组件称为 Callgrind ,它分析应用程序调用的过程以及这些过程调用的内容等等。名为 KCacheGrind 的应用程序可以可视化 Callgrind 的输出。
|
Note
|
安装 Valgrind
要运行此处的示例,需要将 Valgrind 工具与 KCacheGrind 一起安装。如果您使用的是Linux,这些工具可能已经安装在您的操作系统上。
在Mac OS X上, 您可以使用 Homebrew 轻松安装它们,只需执行
brew install valgrind QCacheGrind 。
|
让我们在 [listing_1_4,清单1.4] 中的示例应用程序上试试Valgrind。
首先通过运行 nim c main 在没有编译标志的情况下重新编译。需要注释掉 main.nim 文件中的 import nimprof 行才能成功完成此操作。
然后,执行命令: valgrind --tool=callgrind -v ./main ,就可以在 Valgrind 下运行此应用程序了。
callgrind 工具比 Nim 分析器增加了更大的开销,因此您可能需要终止应用程序,同时按下 Control+C 来安全地终止应用程序。
callgrind 工具提供的文本输出非常大,因此不能用文本编辑器中查看所有内容。幸好有一个工具可以让我们直观地探索它。此工具称为 KCacheGrind (Mac OS X 上的 QCacheGrind)。您可以在执行 Valgrind 的目录中执行它,以获得类似于 [figure_1_3,图1.3] 中截图的内容。
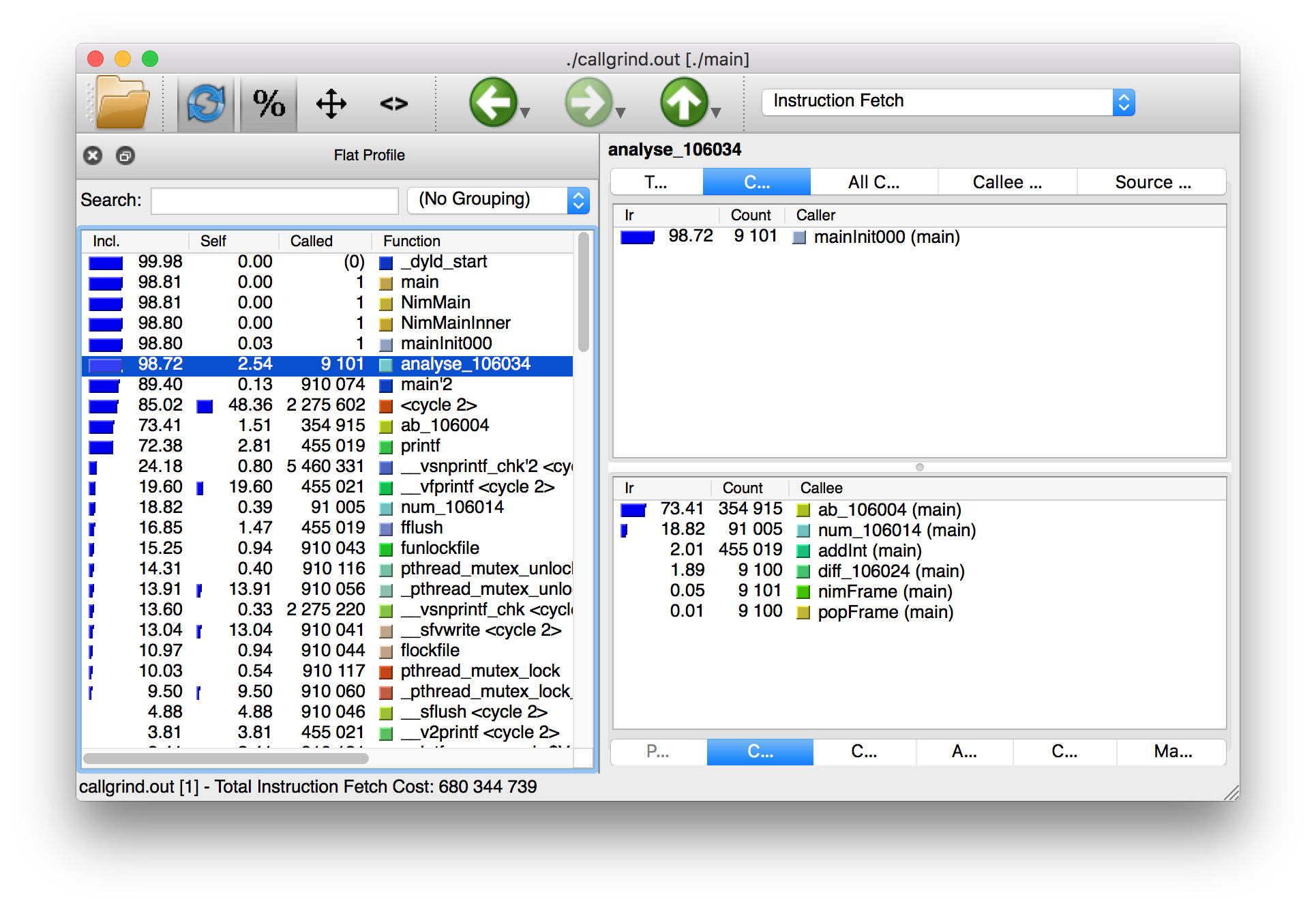
屏幕截图中选择的 C 功能对应于 analyse Nim 程序。当转换为 C 函数时,过程的名称会经历一个称为"名称修改"的过程,这可以防止和其他 C 函数之间的冲突。名称修改过程目前只是在 C 函数名后面添加一个下划线和一个数字。幸运的是,弄清楚哪些C函数对应于哪个 Nim 过程仍然很容易。
Callgrind 的输出为您提供了有关 Nim 应用程序执行的更多低级细节 图1.3 显示了每个 C 函数执行的次数,它允许您诊断可能超出您控制范围的性能问题。但功能越多,复杂性越大,因此 Valgrind 的学习曲线比 Nim 分析器更难。
调试是软件开发中最重要的活动之一。 软件中的错误是偶然发生的。当用户报告您的软件出现问题时,您如何解决?
第一步是重现问题。之后,调试工具有助于诊断问题并找出其根本原因。
Nim 做了很多事情,使调试尽可能容易。例如,它确保在应用程序崩溃时报告详细且易于理解的堆栈跟踪。看看 清单 1.6 中的代码。
import strutils (1)
let line = stdin.readLine() (2)
let result = line.parseInt + 5 (3)
echo(line, " + 5 = ", result) (4)strutils 模块定义了 parseInt 过程。
从标准输入中读取一行。
字符串 line 被转换为整数,然后再加 5 。
显示计算结果。
这段代码相当简单。它从标准输入中读取一行文本,将该行转换为整数,将加上数字5并显示结果。将此代码保存为adder.nim 并通过执行 nim c adder.nim 来编译,然后执行生成的二进制文件。程序会等待你的输入,当你输入一个数字,你会看到 5 和你输入的数字之和。但是当不输入数字时会发生什么?
输入一些文本并观察结果。您应该在下面的 清单 1.7 中看到类似的输出。
ValueError 的堆栈跟踪Traceback (most recent call last)
adder.nim(3) adder (1)
strutils.nim parseInt (2)
Error: unhandled exception: invalid integer: some text [ValueError] (3)程序正在执行 adder 模块中的第3行…
… 随后是引发 ValueError 异常的 parseInt 过程。
这是一条异常消息,后跟方括号中的异常类型。
程序崩溃是因为引发了异常,并且没有被任何 try语句捕获。结果显示堆栈跟踪并退出程序。 清单 1.7 中的堆栈跟踪非常有用,它直接指向导致崩溃的行。在 adder.nim 模块名称之后,数字 3 指向 adder 模块中的行号。这一行在下面的 清单 1.8 中突出显示。
import strutils
let line = stdin.readLine()
let result = line.parseInt + 5
echo(line, " + 5 = ", result)`parseInt` 过程无法将仅包含字母的字符串转换为数字,因为该字符串中不存在数字。堆栈跟踪底部显示的异常消息通知我们这一点。它包括 `parseInt` 试图解析的字符串值,该字符串值提供了有关错误的进一步提示。
您可能不这么认为,但在调试时,程序崩溃是一件好事。真正可怕的错误是那些不会产生崩溃,但会导致程序产生错误结果的错误。在这种情况下,需要使用高级调试技术。当堆栈跟踪没有提供有关问题的足够信息时,调试也很有用。
调试的主要目的是调查程序执行过程中某一特定点的内存状态。例如,您可能希望在调用 parseInt 过程之前找出line 变量的值。这可以通过多种方式实现。
echo 调试到目前为止,最简单和常见的调试方法是使用 echo 。echo 过程允许您显示大多数变量的值,只要变量的类型实现了 $ 过程,它就可以显示。
对于其他变量,可以使用 repr 过程,您可以将任何类型的变量传递给它,并获得该变量值的文本表示。
使用 repr 过程和 echo ,让我们查看调用 parseInt 之前的line 变量的值。
repr 查看 line 变量的值import strutils
let line = stdin.readLine()
echo("The value of the line variable is: ", repr(line))
let result = line.parseInt + 5
echo(line, " + 5 = ", result)repr 过程很有用,因为它显示不可打印的字符,它还显示了许多类型数据的额外信息。在 listing 1.9 中运行该示例并键入3个Tab字符,将得到以下输出。
The value of the `line` variable is: 0x105ff3050"\9\9\9"
Traceback (most recent call last)
foo.nim(4) foo
strutils.nim parseInt
Error: unhandled exception: invalid integer: [ValueError]异常消息只显示了一些空白,这就是普通文本中 Tab 字符的显示方式。但您无法区分空白是否只是普通的空格字符,还是实际上是多个Tab字符。
repr 过程通过显示 \9\9\9 来解决这种歧义,数字9是制表符的ASCII数字代码。
还显示了 line 变量的内存地址。
writeStackTrace未处理的异常并不是显示堆栈跟踪的唯一方式。
您可能会发现在程序中的任何位置显示当前堆栈跟踪以进行调试非常有用。这可以为您提供重要信息,尤其是在具有许多过程的大型程序中,它可以向您显示通过这些过程的路径以及程序在某个过程中的执行是如何结束的。
看看以下示例。
writeStackTrace 例子proc a1() =
writeStackTrace()
proc a() =
a1()
a()编译和运行这个例子将显示下面的堆栈跟踪。
Traceback (most recent call last)
foo.nim(7) foo
foo.nim(5) a
foo.nim(2) a1首先在第 7 行调用 a 过程,然后在第 5 行调用 a1 ,最后在第 2 行调用 writeStackTrace 过程。
有时,对于真正复杂的问题,适当的调试工具是必要的。与上一节中的分析工具一样,可以使用大多数 C 调试器调试 Nim 程序。最流行的调试工具之一 是 GNU 调试器,它以缩写 GDB 而闻名。
GNU 调试器应该包含在您的 gcc 发行版中,您应该已经将其作为 Nim 安装的一部分。不过新版本的 MacOSX 安装 gdb 是有问题的,但您可以使用类似的调试器 LLDB 。 LLDB 是一个新得多的调试器,但它们的功能几乎完全相同。
让我们尝试使用GDB(如果您在Mac OS X上,则使用LLDB)来调试清单 1.8 中介绍的小 adder.nim 示例。
我将重复下面的示例。
adder.nim 例子import strutils
let line = stdin.readLine()
let result = line.parseInt + 5
echo(line, " + 5 = ", result)为了使用这些调试工具,您需要使用两个附加标志编译 adder.nim 。
--debuginfo 标志,它将指示编译器向生成的二进制文件中添加额外的调试信息。GDB 和 LLDB 将使用调试信息来读取当前执行代码的过程名称和行号。
还有 --linedir:on 标志,它将包含 Nim 特定的调试信息,如模块名称和 Nim 源代码行。GDB 和 LLDB 将使用 --linedir:on 标志添加的信息来报告Nim特定的模块名称和行号。
两个组合在一起,使用以下命令编译 adder 模块: nim c --debuginfo --linedir:on adder.nim。
|
Tip
|
--debugger:native 标志--debugger:native 标志,相当于指定 --linedir:on 和 --debuginfo 标志。
|
下一步是启动调试工具。这两种工具的用法非常相似。要在 GDB 中启动可执行的 adder ,请执行 gdb adder ,在 LLDB 中启动它,请执行lldb adder。GDB 或 LLDB 应该启动,您应该看到类似于 [figure_1_4,图1.4] 或 [figure _1_5,图1.5] 的内容。
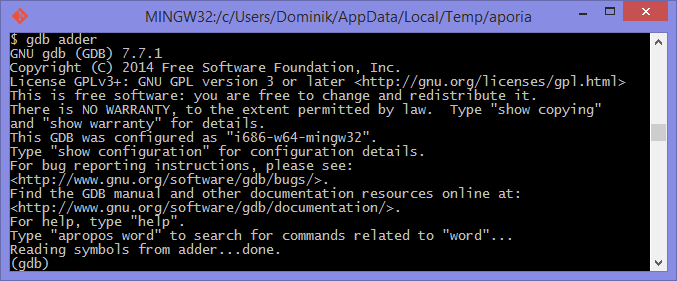
一旦这些工具启动,它们将等待用户的输入。
输入是命令的形式。这两种工具都支持一系列不同的命令,用于控制程序的执行、监视特定变量的值、设置断点等等。要获取支持的命令的完整列表,请键入 help 并按回车键。
这个调试会话的目的是找出 line 变量的值,就像前面的部分一样。为此,我们需要在 adder.nim 文件的第 3 行设置一个断点。幸运的是,GDB 和 LLDB 都使用相同的命令语法来创建断点。只需在终端中键入 b adder.nim:3 ,然后按回车键。
应成功创建断点,调试器将通过显示类似于 Listing 5.23 的消息来确认。
Breakpoint 1: where = adder`adderInit000 + 119 at adder.nim:3, address = 0x0000000100020f17创建断点后,可以使用 run 命令指示调试器运行 adder 程序。在终端中键入 run ,然后按 Enter 键。程序不会命中断点,因为它将首先从标准输入中读取一行,因此在使用 run 命令后,需要在终端中键入其他内容。这一次, adder 程序将读取它。
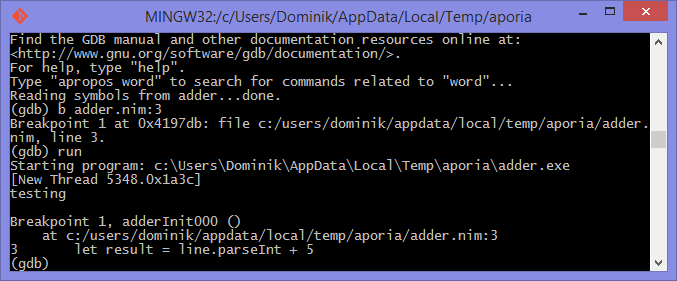
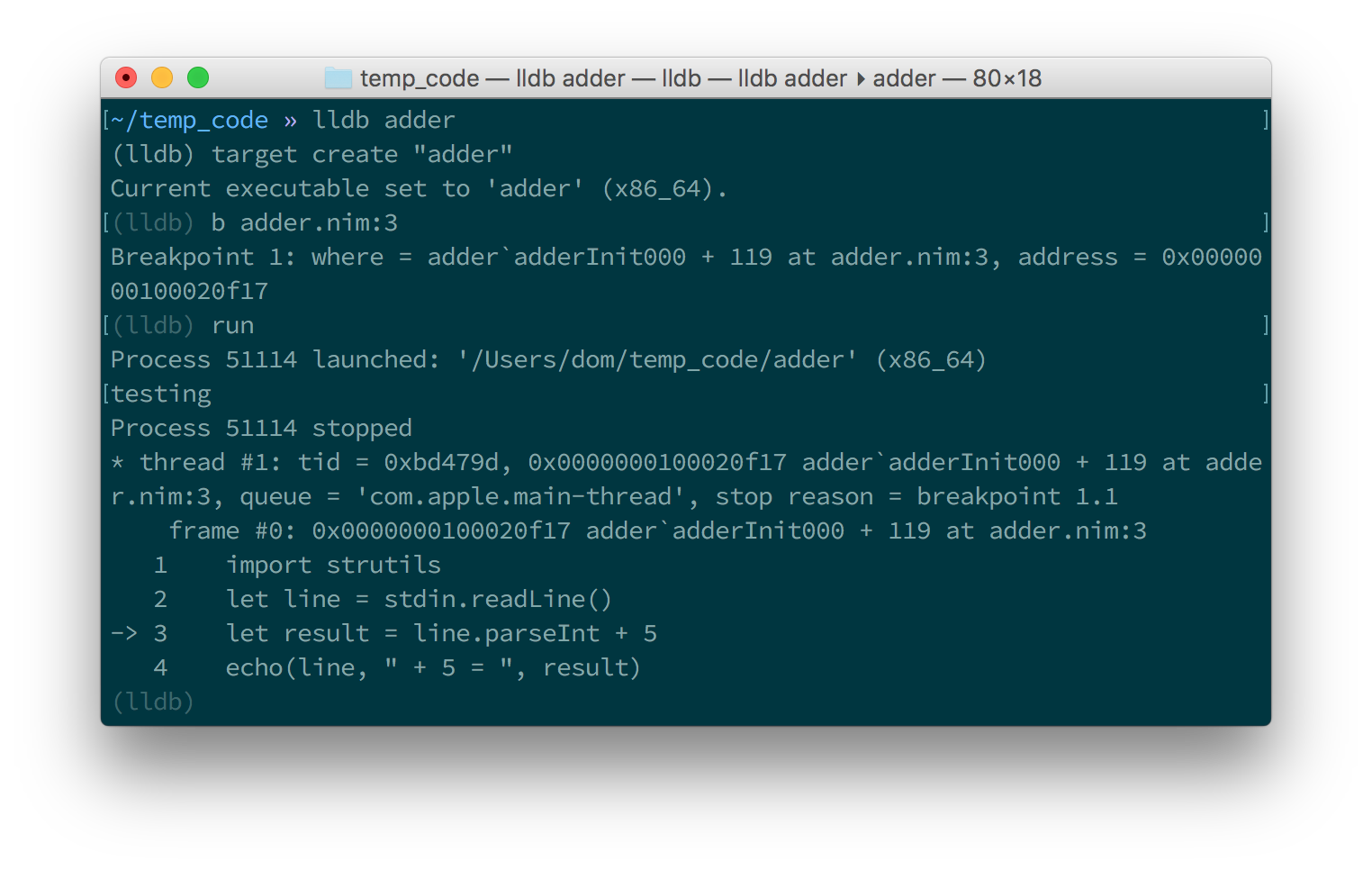
然后,调试器将在第 3 行停止程序的执行。 图 [figure_1_6.1.6] 和 [figure _1_7.1.7] 显示了这将是什么样子。
在程序执行到的这一断点上,我们应该能够显示 line 变量的值。
在 GDB 和 LLDB 中显示变量的值是相同的。
可以使用 p (或 print) 命令显示任何变量的值。
不过,你不能简单地输入 print line 并得到结果。
这是因为我在分析器部分中提到的名称修改。
在打印出 line 变量的值之前,您需要了解它的新名称。在几乎所有情况下,变量名称都只会有下划线,后跟随机数字。
这使得查找名称变得非常简单,但 GDB 和 LLDB 之间的过程不同。
在 GDB 中,查找 line 变量的名称很简单,只需键入 print line_ 并按 Tab 按钮即可。 GDB 将自动为您填写名称,或给您一个选择列表。
至于 LLDB ,因为它不支持通过 Tab 键自动完成,所以这有点复杂。您需要通过查看当前范围中的局部和全局变量列表来查找变量的名称。您可以使用 fr v -a (或 frame variable --no-args) 命令获得局部变量列表, 使用 ta v (或 target variable) 命令获得全局变量列表。line 变量是一个全局变量,因此键入 ta v 以获取全局变量列表。
您应该会看到类似于[figure_1_8,图1.8]中截图的内容。

line 变量的值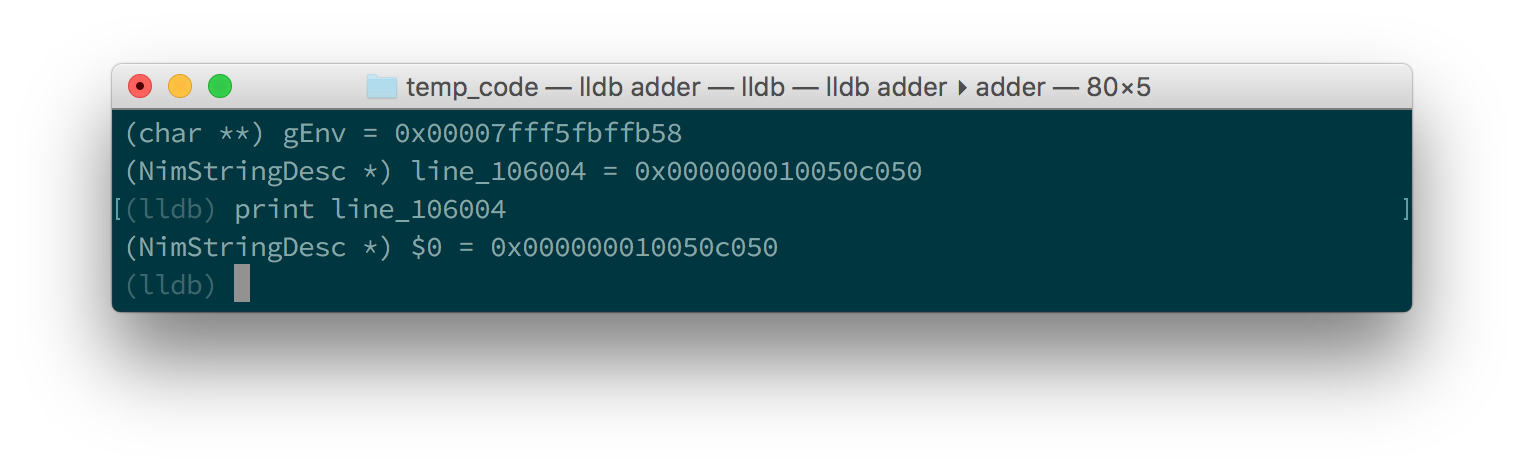
line 变量的值不幸的是,这并没有告诉我们 line 变量的值。我们处于低级 C 的领域,因此 line 变量是指向 NimStringDesc 类型的指针。我们可以通过在变量名的开头添加星号来取消引用此指针: print *line_106004 。
这样做将显示 NimStringDesc 类型中每个字段的值。不幸的是,在LLDB中,这没有显示 data 字段的值,因此我们必须显式访问它: print (char*)line_106004->data 。需要 (char*) 将 data 字段转换为 LLDB 可以显示的内容。图 1.11 和 1.12 分别显示了 GDB 和 LLDB 中的情况。
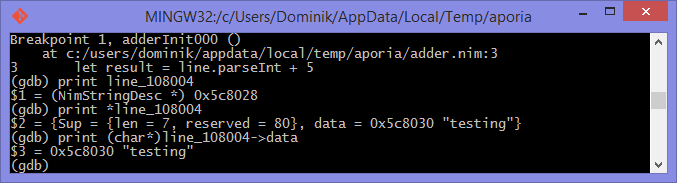
line 变量的值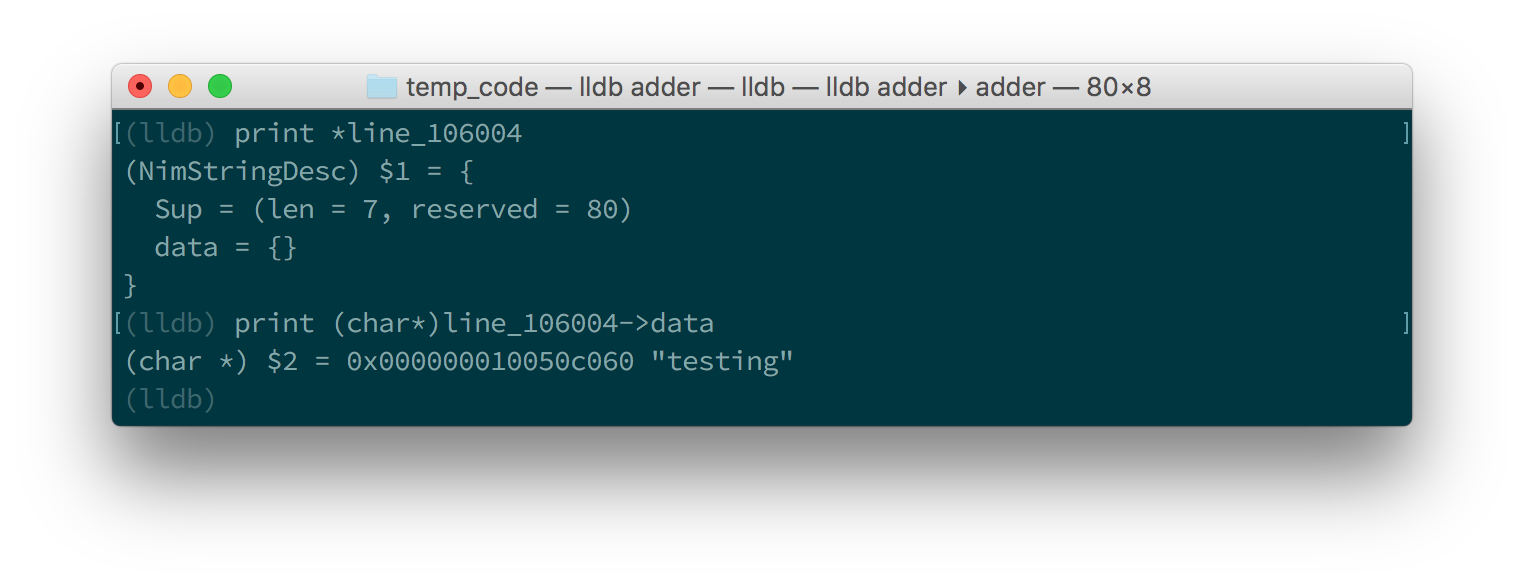
line 变量的值这比简单地使用 echo 过程复杂得多,但对于更复杂的调试场景很有用。希望这能让您了解如何编译 Nim 程序,以便使用 GDB 和 LLDB 对其进行调试。这些调试器提供的更多功能超出了本文的范围。这些功能允许您以许多其他方式分析程序的执行情况。可以通过查看这些调试器和其他许多调试器的在线资源来了解更多信息。
感谢您的阅读。如果您需要有关这些主题或与 Nim 的任何帮助,请与我们 社区 联系。
